

One of the most valuable assets of an organization today is data. Data can be processed by applying business rules to it, and after it is processed, what we end up with is information - the key to making important decisions in any organization.
But sometimes, the data we have gathered does not provide the entire picture. To sort that out, we end up synchronizing our own data with other data repositories. This is something that has to be done in order to have more accurate data; however, this process of synchronizing data is often complicated because of the amount of work that has to be completed.
Synchronizing data is often tedious work because organizations do not want others to touch the database they are responsible for. This is typical because only the IT department's inner circle is able to understand the structure and the meaning of their data.
The other problem is that sometimes data is not separated from the application logic they were conceived for and, thus, cannot be reused as easily as it should be.
Synchronizing data for these types of repositories is complex because to match the IDs of one database entity into our own, and we sometimes end up creating another table mapping the external IDs with our own IDs in order to have a 'track' on how to find the external information. This approach is very messy and time-consuming largely because we end up storing tables of indexes whose purposes are just intended to provide a hint of where to find things instead of storing the actual data with meaning.
If we focus on a meaningful description of the data itself instead of designing our databases after the applications they are going to serve, we can then save a lot of time and avoid costly problems.
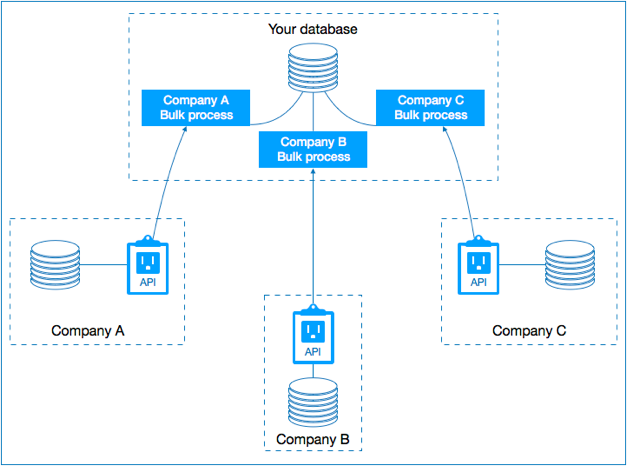
A traditional database synchronization process. Slow, messy, and prone to data duplication.
To sort this out, let's talk about Linked Open Data. Open data means that data is open to any kind of application, and to achieve this, we can make use of open standards like RDF to describe metadata. But what about the link in Linked Open Data?
Nowadays, the concept of linking web pages using hyperlinks is natural and basic, but think about how groundbreaking this was 20 years ago.
Today we are in a similar situation but with data instead of pages.
Because many organizations do not understand the concept of publishing data on the web, let alone why data on the web should be linked, we have not yet been able to evolve the web into the next web.
By having a Linked Open Data repository, your data is easily exposed to the web through the use of URLs. Once you visit a URL, you can then see the content of an entity living in your database. This is powerful because it not only allows us to easily consume/manipulate data stored this way but because it also allows us to use URLs to easily link data between many Linked Open Data repositories!
Another benefit of using Linked Open Data repositories is that they provide meaning to the data itself, allowing machines to also understand it, not just humans. This is possible because the majority of these repositories demand data to be stored with open standards that provide meaning to what's being stored.
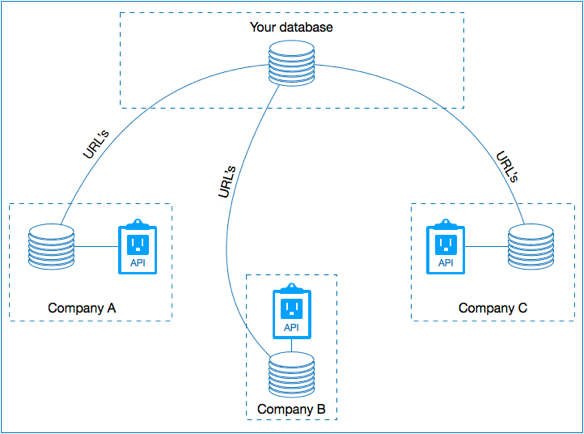
Linking entities between different domains with Linked Data. Each domain stores its own data; an entity can be used in any database with its own URL.
One good example is a company we helped to move to a Linked Open Data repository. It was a parts manufacturing company. Let's call it Base22 Parts Inc.
What they wanted was to track the orders that shipped a specific piece easily, but they also wanted to know why that piece was malfunctioning and the ability to view the results of each piece's quality tests. Because they also wanted to graphically view all of the above using a dashboard, they needed to expose their data through an API.
Because of this, we decided to use Carbon LDP to migrate all their data into a Linked Data repository so they could easily track such requirements, but also allow them to expose their data through an integrated RESTful API so they could easily consume it in any web app or mobile app.
By using Linked Data repositories instead of storing data the "old fashioned" way, we can reduce the time and effort or synchronize data among repositories and focus on building the data-consuming applications instead.
To learn more about the link in Linked Data, contact us here. We look forward to introducing your company to the Next Web.











