

Uno de los activos más valiosos que tiene hoy en día una organización son los datos. Estos pueden procesarse conforme a determinadas reglas de negocio y, con ello, obtenemos información: la clave para la toma de decisiones importantes en cualquier organización.
Aunque a veces, los datos que hemos reunido no nos proporcionan un panorama completo y, para solucionarlo, terminamos sincronizando nuestros datos con otros repositorios. Requerimos hacerlo si deseamos tener valores más precisos; sin embargo, este proceso de sincronización usualmente es complicado debido a la cantidad de trabajo que debe realizarse.
Generalmente, sincronizar datos es un trabajo tedioso porque las organizaciones no quieren que otros accedan a la base de datos de la que son responsables. Esto pasa porque muchas de las veces solo el círculo interno del departamento de TI puede comprender la estructura y el significado de sus datos.
El otro problema es que, a veces, los datos no están separados de la lógica de aplicación en la que fueron creados y, por lo tanto, no se pueden reutilizar tan fácilmente como deberían.
La sincronización de datos para este tipo de repositorios resulta compleja porque, para hacer coincidir el ID de una entidad de una base de datos dentro de nuestra base, terminamos creando otra tabla para mapear los ID externos con nuestros propios ID para tener un “rastro” sobre cómo encontrar la información externa. Este enfoque es muy complicado y toma mucho tiempo implementarse, en gran parte, porque terminamos almacenando tablas de índices cuyo propósito es proporcionarnos una “pista” de dónde encontrar cosas, en lugar de almacenar los valores que tienen significado.
Si nos enfocáramos en la descripción significativa de los datos en lugar de diseñar nuestras bases de datos conforme a las aplicaciones a las que van a contribuir, podríamos ahorrarnos mucho tiempo y evitarnos problemas que serían costosos.
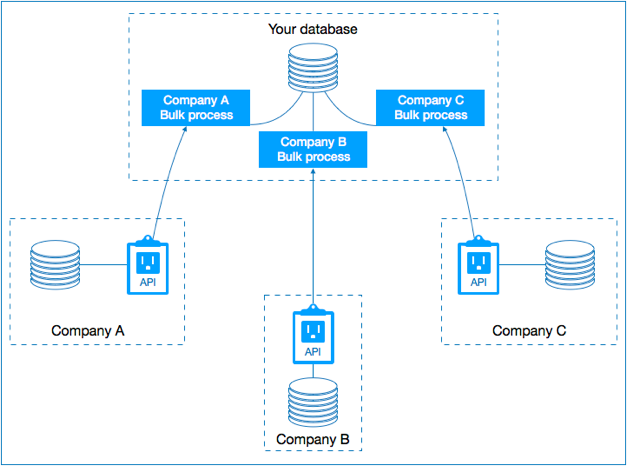
Un proceso tradicional de sincronización de bases de datos. Lento, complicado y propenso a la duplicación de valores.
Para solucionar esto, hablemos de Linked Open Data.
Open Data significa que los datos están disponibles para cualquier tipo de aplicación y, para lograr esto, podemos hacer uso de estándares abiertos como RDF para describir los metadatos. ¿Pero dónde queda el enlace en Linked Open Data?
Hoy en día, vincular páginas web mediante hipervínculos es algo fundamental y muy común, pero solo imagínate lo innovador y revolucionario que fue esto hace 20 años.
Actualmente estamos en una situación similar, pero vinculando datos en lugar de páginas.
Debido a que muchas organizaciones no entienden el concepto de publicación de datos en la web y mucho menos por qué deberían estar vinculados, aún no hemos podido provocar una evolución en la web que la lleve al siguiente nivel.
Cuando tienes un repositorio Linked Open Data, tus datos se pueden publicar fácilmente en la web mediante el uso de una dirección URL. Una vez que visitas una URL, puedes ver el contenido de una entidad que vive en tu base de datos. ¡Esto es poderosísimo porque no solo nos permite consumir/manipular de forma sencilla los datos almacenados de esta manera, sino que también nos permite usar una URL para vincular fácilmente los datos entre muchos repositorios de datos abiertos vinculados!
Otro beneficio de usar los repositorios Linked Open Data es que proporcionan significado a los datos en sí, permitiendo que las máquinas también lo entiendan, no solo los humanos. Esto es posible porque la mayoría de estos repositorios exigen que los datos se almacenen con estándares abiertos que brindan significado a lo que se está almacenando.
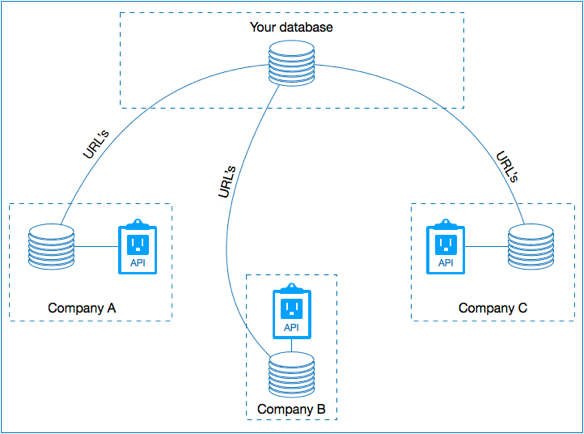
Vinculación de entidades entre diferentes dominios con Linked Data. Cada dominio almacena sus propios datos; una entidad se puede usar en cualquier base de datos con su propia URL.
Un buen ejemplo de esto lo podemos ilustrar con una empresa a la que ayudamos a cambiarse a un repositorio Linked Open Data. Era una empresa de fabricación de piezas, así que llamémosla Base22 Parts Inc.
Lo que esta empresa quería era rastrear fácilmente los pedidos que enviaban de una pieza en específico, pero también querían saber a qué se debía su mal funcionamiento, así como tener la capacidad de ver los resultados de las pruebas de calidad de cada pieza. Asimismo, querían visualizar gráficamente todo lo anterior usando un dashboard, por lo que la empresa necesitaba exponer sus datos a través de una API.
Debido a esto, decidimos usar Carbon LDP para migrar todos sus datos a un repositorio Linked Data para que pudieran rastrear fácilmente dichos requisitos, pero que también les permitiera exponer sus datos a través de una RESTful API integrada para visualizarlos fácilmente en cualquier aplicación web o móvil.
Mediante el uso de repositorios Linked Data, en lugar de almacenar datos “a la antigua”, podemos reducir tiempo y esfuerzos en sincronizar datos entre los repositorios, y centrarnos en la creación de aplicaciones que consumen datos.
Para obtener más información sobre el enlace en Linked Data, contáctanos aquí. Esperamos poder llevar a tu empresa al siguiente nivel de la web.











