

When reading about Linked Data and the Semantic Web, you might not realize that one of the main objectives these standards aim for is improving data value. A way of achieving this is to make data readable to computers. Now, how is this accomplished within the world of Linked Data? Well, to begin, you simply describe your data, and to do this, you can use a readily defined Resource Description Framework (RDF). While RDF is a popular concept within Linked Data, many people might not grasp exactly what it is or why it is useful, so let's find out.
RDF, as its name states, is a framework to describe resources used on the web. It is a standard developed by the World Wide Web Consortium (W3C) intended to describe metadata - data of data. This description allows computers to understand the information contained in your human-readable document, and the fact that it is standardized provides a set of rules for collaborative systems to understand each other's data. The way you describe data when using RDF is through simple statements that have a subject, a predicate, and an object.
Take as an example the phrase: "Paul lives in San Francisco". We are stating something about Paul. Therefore, that is the subject we are talking about. Now, what are we stating about him? Where he lives, which is the predicate or verb in our statement. Finally, San Francisco is the object the predicate is referring to. Given the three parts in every RDF statement, they are also known as triples. This statement, written in a different manner, is a simple example of RDF.
There are multiple syntaxes you can use to write RDF, which is great because you get multiple options to choose from. The most popular ones are JSON-LD, TriG, Turtle, and XML RDF. The W3C has developed specifications for these, which you can find on the W3C website.
For example, here's our previous sample phrase written using TriG:
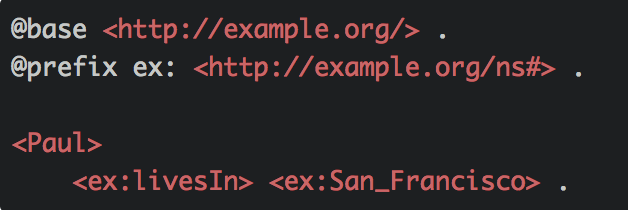
There are a lot of advantages when working with RDF. For starters, data becomes semantic or self-explanatory, which is excellent for data integration and interoperability. Furthermore, if both Paul and San Francisco are resources defined in a graph, then that statement describes the link between the two resources. Therefore, a set of RDF statements can be translated into a graph of linked resources and vice versa.
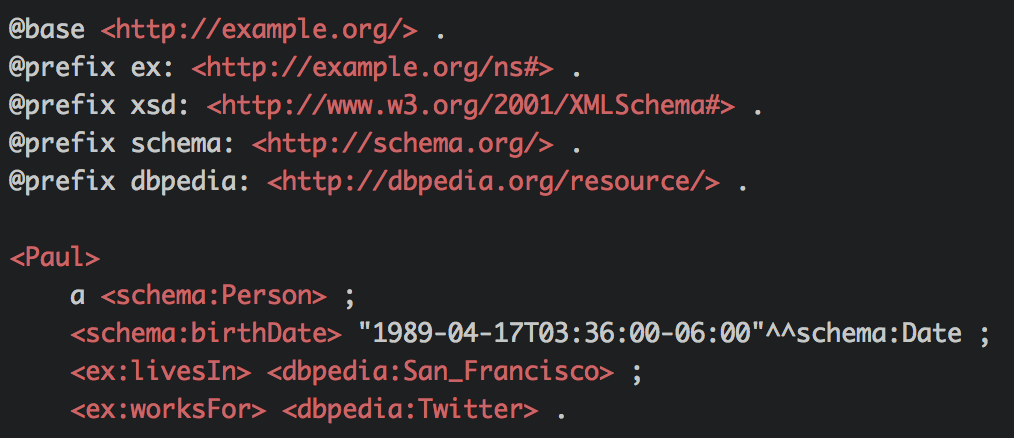
RDF statements.
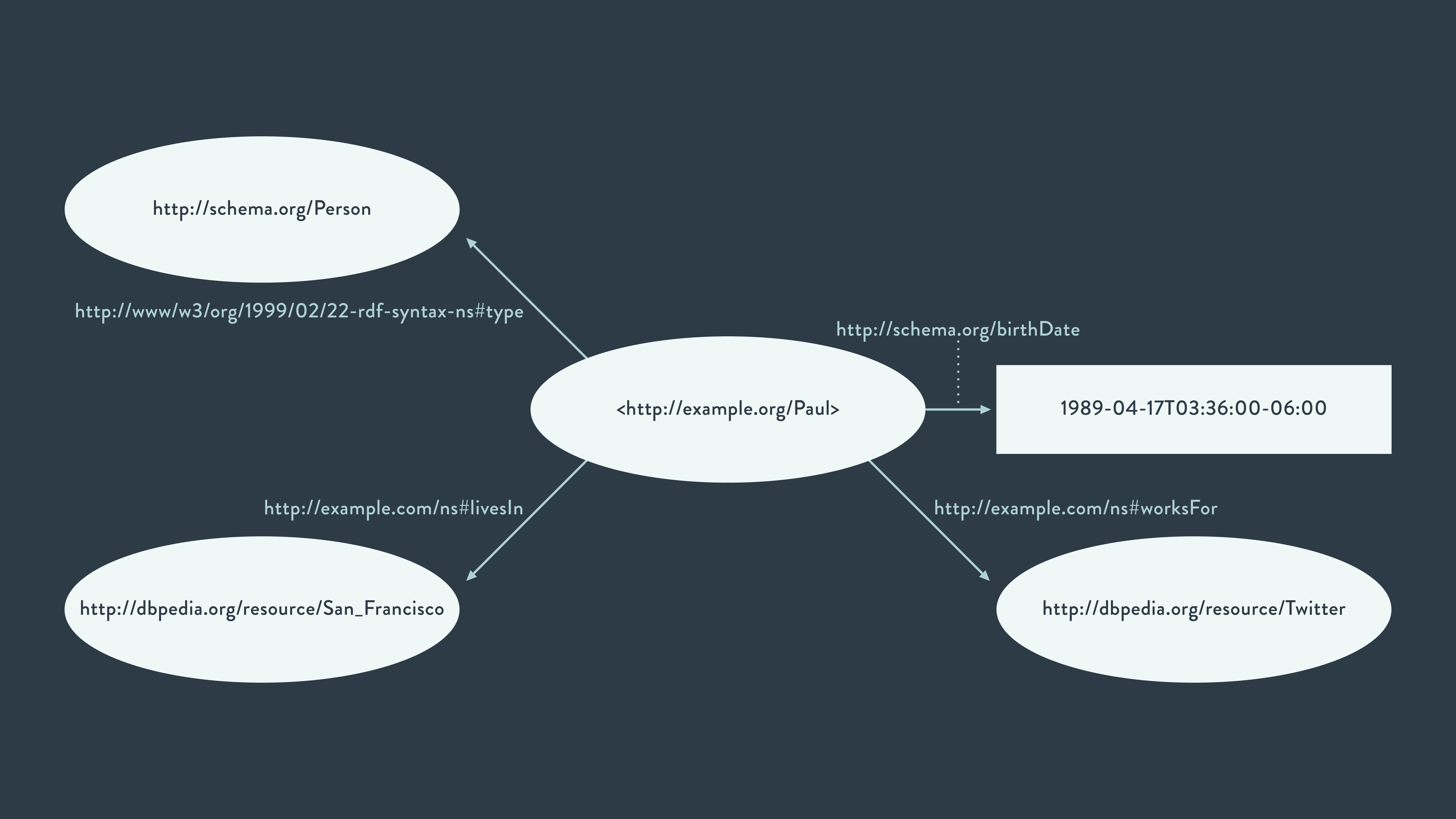
Graph of linked resources.
Also, with RDF, you now have extremely flexible resources since modifications consist of adding or removing RDF triples. If Paul moved from San Francisco, you would only need to remove that statement, deleting the link between the two resources without affecting the rest of your graph. Forget about dealing with static schemas and complex table modifications.
What's more, given that the resources and predicates in RDF statements are defined within a namespace, you can generate data models that are reusable. Also, you can use data models that already exist, such as http://schema.org. This is only one example of multiple specialized models that are public and available online. Finally, use data from different sources to empower your own data. Remember combining graphs has no cost, so look through the public data repositories already described using RDF and include them within your graphs to get more from your data for free.
Carbon LDP uses all the power provided by RDF to maintain your data, allowing you to benefit from all the advantages we listed before with a simple setup procedure. With Carbon LDP, you can use RDF within your back-end to escalate your data with external repositories, reuse your data models between applications, and benefit from all the advantages Linked Data provides.
To learn more about RDF or Carbon LDP, reach out to us here.











